在自动驾驶感知系统的研发过程中,模型的性能高度依赖于大规模、高质量的感知数据集。目前业界常用的数据集包括 KITTI、nuScenes、Waymo Open Dataset 等,它们为自动驾驶算法的发展奠定了重要基础。
然而,构建真实世界的感知数据集并非易事——不仅需要投入大量人力、物力与时间成本,还需要面对数据采集受限、隐私合规、标注耗时以及极端场景难以获取等诸多挑战。
在此背景下,高保真虚拟数据集正成为自动驾驶感知算法研究的新方向。通过仿真平台生成的虚拟数据,不仅能够快速扩充数据规模,还可灵活构造复杂路况、恶劣天气及罕见事件,为模型提供更全面的训练样本。
基于此,康谋推出了全新的高保真虚拟数据集——SimData。SimData依托aiSim的高精度物理建模与逼真视觉渲染能力,能够生成多传感器同步数据(包括相机、激光雷达、雷达、IMU 等),实现与真实世界数据一致的多模态特性。
SimData数据结构严格遵循nuScenes数据集格式规范,可直接使用官方nuscenes-devkit工具解析和可视化,大幅降低开发者上手成本。
本文将介绍SimData的核心特性与构建流程,并展示其在典型感知任务中的表现。SimData 正式版及相关对比测试报告将于近期发布,敬请持续关注康谋的最新动态。
02 SimData构建过程
传感器布局
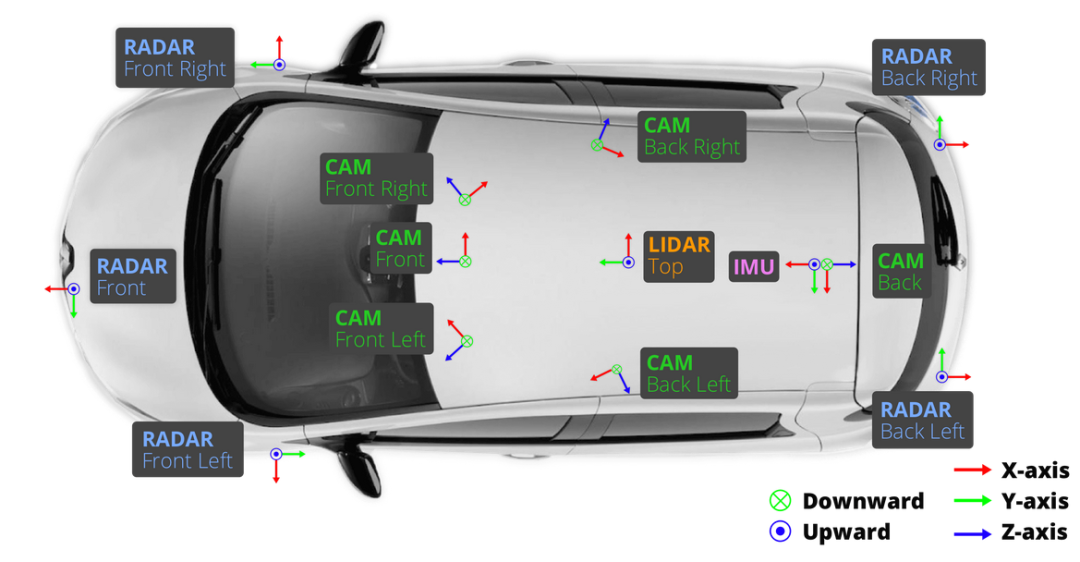
在 aiSim 仿真平台中,我们严格复现了nuScenes 数据集的传感器布局,以确保数据结构和多模态同步特性的一致性。
仿真车辆共配置了 6 路环视相机、5 个雷达(Radar)、1 个激光雷达(LiDAR)、1 个惯性测量单元(IMU)以及 1 个定位系统(GPS)。
其中,相机与雷达的采样频率均为 40 Hz,激光雷达的采样频率为 80 Hz,能够满足高时序精度的多传感器同步采集需求。
各传感器的空间布设与朝向如下图所示:

整体视图(左)、前视图(右)

左视图(左)、顶视图(右)
与 nuScenes 不同的是,SimData中所有传感器均采用FLU(Forward–Left–Up) 坐标系,而在 nuScenes 数据集中,相机传感器使用的是RDF(Right–Down–Forward)坐标系。
在数据构建过程中,我们对所有标注文件进行了严格的坐标系转换与对齐处理,确保坐标定义在逻辑上与 nuScenes 完全一致。
因此,用户在使用 SimData 时,无需额外关注坐标差异,其数据解析与开发体验与 nuScenes保持一致。下图展示了nuScenes中各传感器的典型布局及其坐标系定义。
数据结构
SimData 数据集在结构设计上与 nuScenes 完全保持一致。对于已经熟悉 nuScenes 的开发者而言,无需额外的适配或学习成本,即可快速上手SimData 的使用与解析。
下图展示了 SimData 数据集的整体目录结构,nuScenes 同样遵循这一组织形式,以实现无缝兼容与工具级互通。
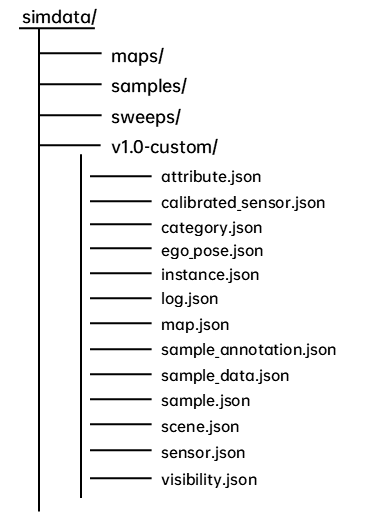
具体说明如下:

maps文件夹
存放数据集中使用到的所有高精地图图像文件,用于提供地理位置信息和场景背景参考。
samples文件夹
存放各类传感器的关键帧数据,包括:
- 6 路摄像头图像(.jpg文件)
- 5 路雷达点云(.pcd文件)
- 1 路激光雷达点云(.bin文件)
其中,每隔0.5 秒抽取一帧数据作为关键帧进行保存。
sweeps文件夹
保存除关键帧以外的连续传感器数据,用于构建时序信息和多帧融合任务。
v1.0-*文件夹
存放传感器的标注与元数据信息,所有文件均以.json格式保存,涵盖时间戳、姿态参数、标注标签、场景描述等内容。
各个json标注文件的关系网络也与nuScenes数据集保持一致,这里以nuScenes官方文件结构图进行说明:
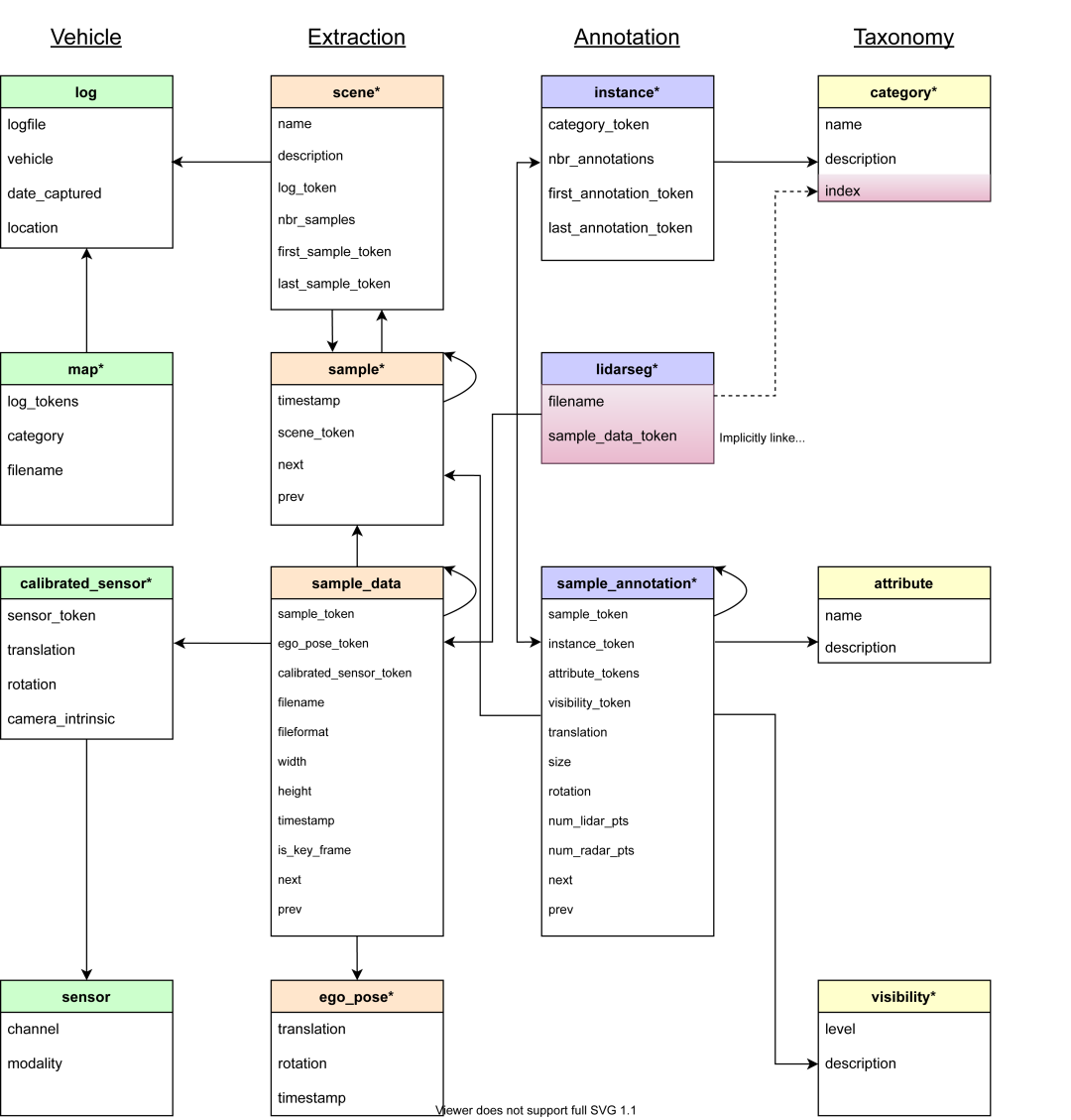
在 SimData 数据集中,每个文件中的信息块均通过一个全局唯一的 UUID(Universally Unique Identifier) 作为token进行标识。
这些 token 构成了数据集中不同信息之间的关联桥梁,用户可通过sample.json、sample_data.json 和 sample_annotation.json三个核心文件获取绝大多数标注与结构化信息。
sample.json
sample.json文件记录了关键帧(Keyframe)的基础信息。
- 每个关键帧都对应一个sample_token,用于唯一标识该帧数据。
- 通过scene_token可在scene.json文件中查找到该样本所属的场景。
- 文件中还提供了 前一帧 (prev) 与 后一帧 (next) 的token,可用于构建连续帧关系。
sample_data.json
利用sample_token可在sample_data.json 中获取对应帧的多传感器数据详情,包括:
- ego_pose_token:车辆自车位姿的引用,可在 ego_pose.json 中获得该时刻的位姿信息(位置与朝向)。
- calibrated_sensor_token:对应传感器的标定参数,可在 calibrated_sensor.json 中查询到该传感器的内参与外参信息。
- filename:传感器原始数据的文件路径。若为相机数据,还包含图像的高度(height)与宽度(width)。
- timestamp:时间戳(单位:微秒),用于多传感器时间同步。
- is_key_frame:布尔值,指示该帧是否为关键帧。
- next / prev:分别指向下一帧和前一帧的 token,实现时序关联。
sample_annotation.json
sample_annotation.json文件记录了每个关键帧中检测到的目标物体信息,可通过 sample_token 进行关联。包含的主要字段如下:
(1)instance_token:目标实例的唯一标识。
可在 instance.json 中查询到该实例对应的 category_token(类别信息)、首次与最后出现的关键帧 token。
通过 category_token 可进一步在 category.json 中获取该实例的具体类别名称。
(2)visibility_token:
可见度等级标识(共四级,数值越大表示可见度越高),其定义可在 visibility.json 中查阅。
(3)目标几何与姿态信息,这些位姿均定义在传感器坐标系下。
中心点位置 (translation)
尺寸大小 (size)
旋转角度 (rotation),以 四元数(Quaternion) 形式存储
(4)点云统计信息
检测框中包含的激光雷达点数 (num_lidar_pts) 与 雷达点数 (num_radar_pts)。
(5)前后帧关联
分别记录该实例在前一帧与后一帧中的对应 token。
03 SimData与感知模型使用示例
使用方法与真值可视化
SimData可以直接使用nuScenes-devkit进行解析,使用方法与nuScenes数据集一致。示例:
1. from nuscenes.nuscenes import NuScenes
2. nusc = NuScenes(version='v1.0-custom', dataroot=data_path, verbose=True)
得到示例化对象后便可以使用nuScenes官方提供的工具对SimData进行分析和模型训练。配合cv2或matplotlib可以对数据集进行可视化:
具有gt框的六路摄像头输出:
同步lidar点云,可以同时绘制出bev视角下的标注信息


bevformer检测效果展示
以下是使用在nuScenes数据集下训练的权重,采用bevformer-tiny模型直接进行检测的效果(即没有在SimData上进行训练)。
1. bevformer官方代码库:https://github.com/fundamentalvision/BEVFormer/tree/master
2. bevformer论文:https://arxiv.org/pdf/2203.17270
04 总结
本文阐述了虚拟数据集在自动驾驶感知研究中的重要性,并介绍了基于aiSim仿真平台生成的高保真虚拟感知数据集——SimData。
文章详细说明了 SimData 的数据组成结构与使用方法,并利用开源感知模型对其进行了检测验证,从而验证了数据集的可用性与有效性。
后续,康谋团队将发布更为详尽的测试与对比报告,以进一步验证SimData与真实数据集之间的高一致性。通过这一系列工作,我们不仅证明了aiSim仿真环境的高保真特性,也为研究者与开发者提供了一个高质量、易用且可扩展的虚拟感知数据资源,以持续助力自动驾驶感知算法的研究与训练。
- 随机文章
- 热门文章
- 热评文章
- 以太网入门:从零开始,掌握以太网基础知识!
- 泰克示波器MSO6B与上一代MSO5对比
- 安泰电子:功率放大器可以进行哪些测试
- 光纤是干嘛的
- 凯米斯科技COD-408在线COD传感器:开启水质监测新时代
- 突破人形机器人物理限制,MPS全栈方案让开发者无惧三大挑战
- 国产化浪潮下的智慧办公新选择——蝶云智控海光OPS电脑全线解决方案
- 血液制品行业大动作!行业一季度净利润普遍下滑 增长公司仅此一家!